 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMH-Bench: Benchmarking LLM Agents for Environment-Grounded Reasoning and Action in Smart Homes
Jun 01, 2026Smart homes are evolving toward complex state-dependent living environments, requiring Large Language Models (LLMs) to reason over user intent, preferences, and multi-device interactions. However, existing smart-home benchmarks often focus on static instruction-to-API mapping or limited simulations, failing to evaluate whether LLMs can reason, interact, and act reliably in realistic household scenarios. To address these limitations, we introduce SMH-Bench, a comprehensive benchmark for evaluating LLMs in smart-home environments. Built upon HomeEnv, an executable and verifiable smart-home simulator, SMH-Bench contains 1,100 high-quality tasks spanning 7 categories and 22 fine-grained subcategories. It further stratifies tasks across simple, medium and complex homes, ranging from small apartments to dense multi-room environments with 135 devices. Experiments show that although frontier LLMs achieve strong performance on explicit control and query tasks, they still exhibit significant weaknesses in automation task scheduling, ambiguity handling and personalized reasoning, especially as home complexity increases. We hope SMH-Bench will facilitate the development of more reliable, context-aware, and practically deployable smart-home agents.
HomeFlow: A Data Flywheel for Smart Home Agent Training with Verifiable Simulation
May 31, 2026Large language model agents are moving beyond text-only interaction toward physical-world control, with smart homes as a representative domain. Real domestic interaction requires understanding ambiguous intents, operating in dynamic environments, and performing multi-turn reasoning. However, existing methods struggle to generate high-quality training data for smart home agents. We propose HomeFlow, a verifiable data flywheel for this domain. HomeFlow uses HomeEnv as a unified simulation environment and HomeMaker to procedurally generate diverse home settings. Subsequently, Blueprint compiles open-ended user intents into executable state-based success conditions, while MCTS-Flow synthesizes diverse, verifiable multi-turn trajectories through environment-guided tree search. We then optimize the agents via supervised fine-tuning and step-wise RLVE, which facilitates iterative improvement through authentic physical feedback. We further construct SmartHome-Bench to evaluate the agent across various smart home tasks. On this benchmark, HomeFlow-RL-4B and HomeFlow-RL-8B achieve task success rates of 84.60% and 87.03%. It is worth noting that HomeFlow-RL-8B even surpasses the leading GPT-5.5 by 1.23 percentage points.
Multimodal Learning on Low-Quality Data with Conformal Predictive Self-Calibration
May 05, 2026Multimodal learning often grapples with the challenge of low-quality data, which predominantly manifests as two facets: modality imbalance and noisy corruption. While these issues are often studied in isolation, we argue that they share a common root in the predictive uncertainty towards the reliability of individual modalities and instances during learning. In this paper, we propose a unified framework, termed Conformal Predictive Self-Calibration (CPSC), which leverages conformal prediction to equip the model with the ability to perform self-guided calibration on-the-fly. The core of our proposed CPSC lies in a novel self-calibrating training loop that seamlessly integrates two key modules: (1) Representation Self-Calibration, which decomposes unimodal features into components, and selectively fuses the most robust ones identified by a conformal predictor to enhance feature resilience. (2) Gradient Self-Calibration, which recalibrates the gradient flow during backpropagation based on instance-wise reliability scores, steering the optimization towards more trustworthy directions. Furthermore, we also devise a self-update strategy for the conformal predictor to ensure the entire system co-evolves consistently throughout the training process. Extensive experiments on six benchmark datasets under both imbalanced and noisy settings demonstrate that our CPSC framework consistently outperforms existing state-of-the-art methods. Our code is available at https://github.com/XunCHN/CPSC.
Codebook-Centric Deep Hashing: End-to-End Joint Learning of Semantic Hash Centers and Neural Hash Function
Nov 15, 2025



Hash center-based deep hashing methods improve upon pairwise or triplet-based approaches by assigning fixed hash centers to each class as learning targets, thereby avoiding the inefficiency of local similarity optimization. However, random center initialization often disregards inter-class semantic relationships. While existing two-stage methods mitigate this by first refining hash centers with semantics and then training the hash function, they introduce additional complexity, computational overhead, and suboptimal performance due to stage-wise discrepancies. To address these limitations, we propose $\textbf{Center-Reassigned Hashing (CRH)}$, an end-to-end framework that $\textbf{dynamically reassigns hash centers}$ from a preset codebook while jointly optimizing the hash function. Unlike previous methods, CRH adapts hash centers to the data distribution $\textbf{without explicit center optimization phases}$, enabling seamless integration of semantic relationships into the learning process. Furthermore, $\textbf{a multi-head mechanism}$ enhances the representational capacity of hash centers, capturing richer semantic structures. Extensive experiments on three benchmarks demonstrate that CRH learns semantically meaningful hash centers and outperforms state-of-the-art deep hashing methods in retrieval tasks.
In-situ monitoring additive manufacturing process with AI edge computing
Jan 02, 2023



In-situ monitoring system can be used to monitor the quality of additive manufacturing (AM) processes. In the case of digital image correlation (DIC) based in-situ monitoring systems, high-speed cameras were used to capture images of high resolutions. This paper proposed a novel in-situ monitoring system to accelerate the process of digital images using artificial intelligence (AI) edge computing board. It built a visual transformer based video super resolution (ViTSR) network to reconstruct high resolution (HR) videos frames. Fully convolutional network (FCN) was used to simultaneously extract the geometric characteristics of molten pool and plasma arc during the AM processes. Compared with 6 state-of-the-art super resolution methods, ViTSR ranks first in terms of peak signal to noise ratio (PSNR). The PSNR of ViTSR for 4x super resolution reached 38.16 dB on test data with input size of 75 pixels x 75 pixels. Inference time of ViTSR and FCN was optimized to 50.97 ms and 67.86 ms on AI edge board after operator fusion and model pruning. The total inference time of the proposed system was 118.83 ms, which meets the requirement of real-time quality monitoring with low cost in-situ monitoring equipment during AM processes. The proposed system achieved an accuracy of 96.34% on the multi-objects extraction task and can be applied to different AM processes.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021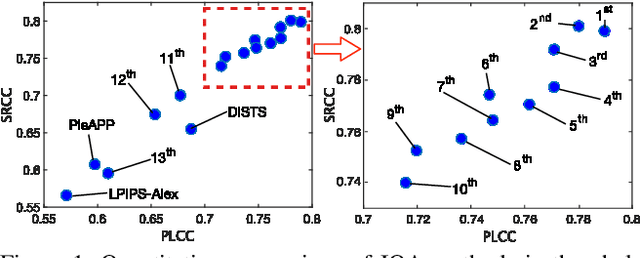
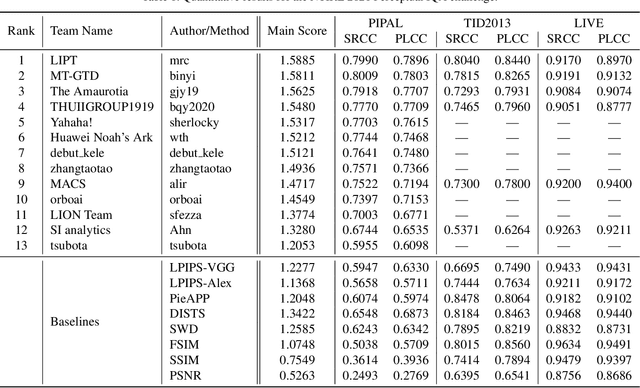

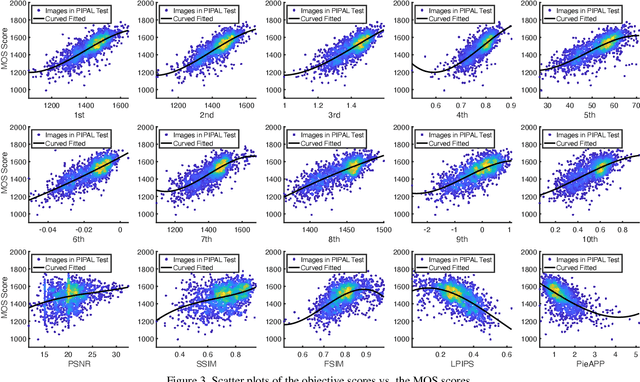
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
CASNet: Common Attribute Support Network for image instance and panoptic segmentation
Jul 17, 2020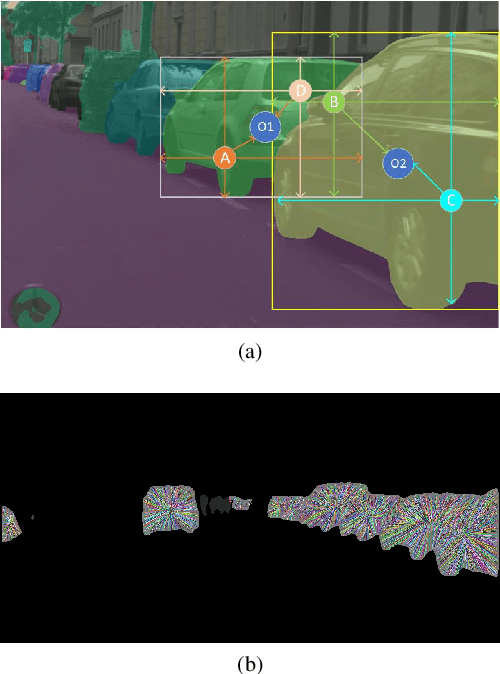
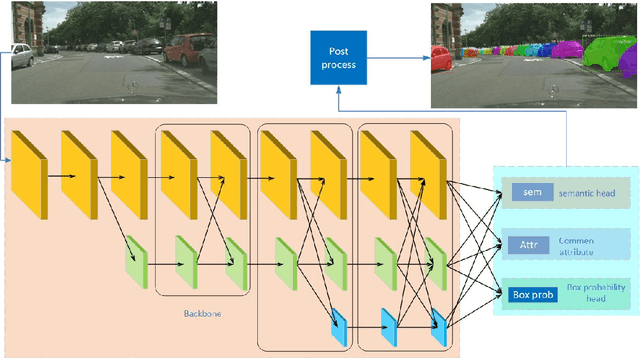
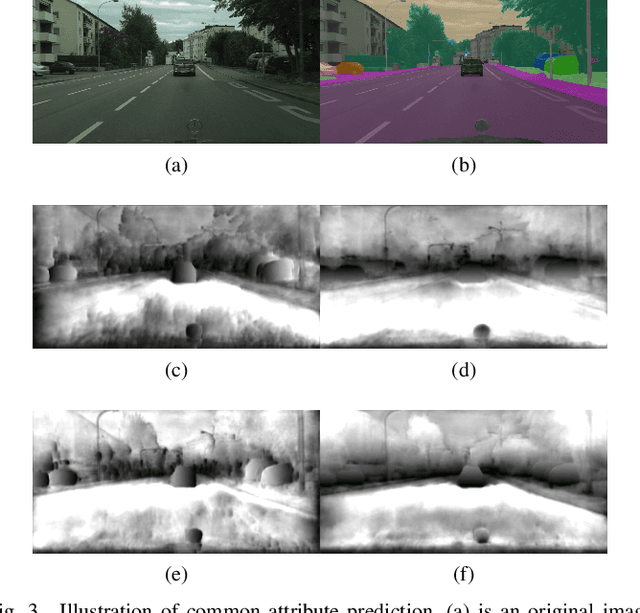

Instance segmentation and panoptic segmentation is being paid more and more attention in recent years. In comparison with bounding box based object detection and semantic segmentation, instance segmentation can provide more analytical results at pixel level. Given the insight that pixels belonging to one instance have one or more common attributes of current instance, we bring up an one-stage instance segmentation network named Common Attribute Support Network (CASNet), which realizes instance segmentation by predicting and clustering common attributes. CASNet is designed in the manner of fully convolutional and can implement training and inference from end to end. And CASNet manages predicting the instance without overlaps and holes, which problem exists in most of current instance segmentation algorithms. Furthermore, it can be easily extended to panoptic segmentation through minor modifications with little computation overhead. CASNet builds a bridge between semantic and instance segmentation from finding pixel class ID to obtaining class and instance ID by operations on common attribute. Through experiment for instance and panoptic segmentation, CASNet gets mAP 32.8% and PQ 59.0% on Cityscapes validation dataset by joint training, and mAP 36.3% and PQ 66.1% by separated training mode. For panoptic segmentation, CASNet gets state-of-the-art performance on the Cityscapes validation dataset.
Image Annotation Incorporating Low-Rankness, Tag and Visual Correlation and Inhomogeneous Errors
Aug 08, 2016
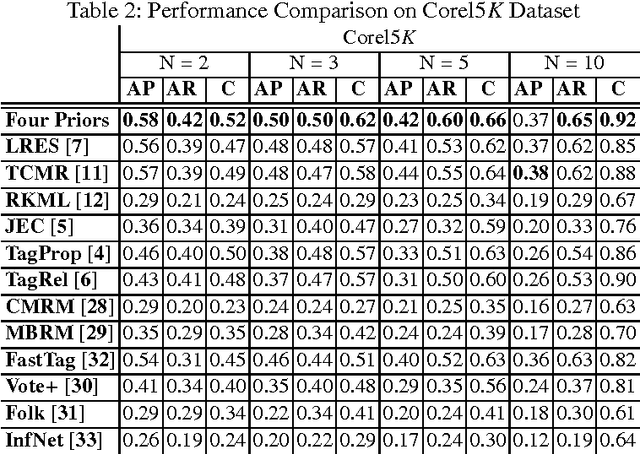
Tag-based image retrieval (TBIR) has drawn much attention in recent years due to the explosive amount of digital images and crowdsourcing tags. However, TBIR is still suffering from the incomplete and inaccurate tags provided by users, posing a great challenge for tag-based image management applications. In this work, we proposed a novel method for image annotation, incorporating several priors: Low-Rankness, Tag and Visual Correlation and Inhomogeneous Errors. Highly representative CNN feature vectors are adopt to model the tag-visual correlation and narrow the semantic gap. And we extract word vectors for tags to measure similarity between tags in the semantic level, which is more accurate than traditional frequency-based or graph-based methods. We utilize the accelerated proximal gradient (APG) method to solve our model efficiently. Extensive experiments conducted on multiple benchmark datasets demonstrate the effectiveness and robustness of the proposed method.
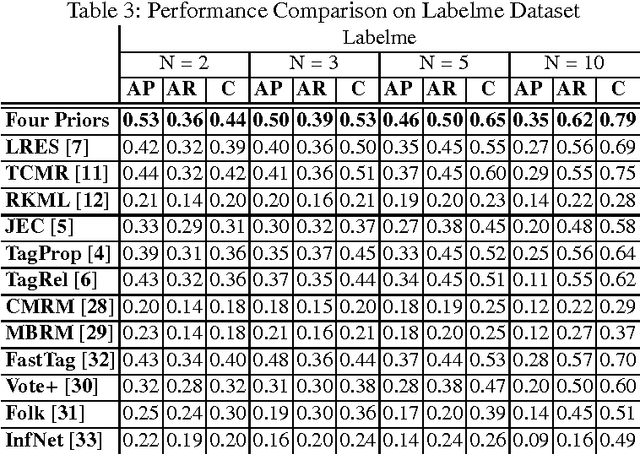
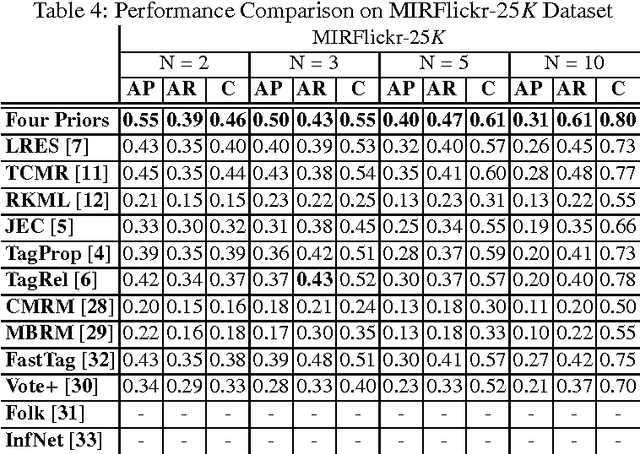
Image Tag Completion and Refinement by Subspace Clustering and Matrix Completion
Aug 08, 2016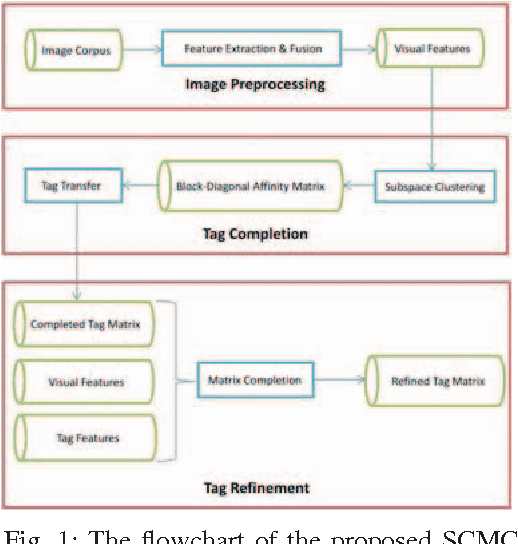


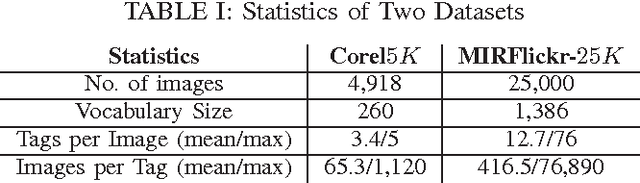
Tag-based image retrieval (TBIR) has drawn much attention in recent years due to the explosive amount of digital images and crowdsourcing tags. However, the TBIR applications still suffer from the deficient and inaccurate tags provided by users. Inspired by the subspace clustering methods, we formulate the tag completion problem in a subspace clustering model which assumes that images are sampled from subspaces, and complete the tags using the state-of-the-art Low Rank Representation (LRR) method. And we propose a matrix completion algorithm to further refine the tags. Our empirical results on multiple benchmark datasets for image annotation show that the proposed algorithm outperforms state-of-the-art approaches when handling missing and noisy tags.
Subspace Clustering Based Tag Sharing for Inductive Tag Matrix Refinement with Complex Errors
Jun 21, 2016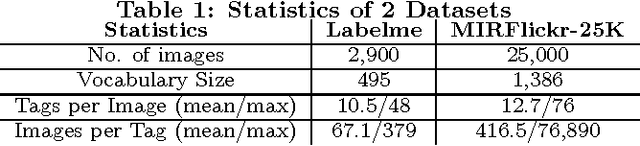
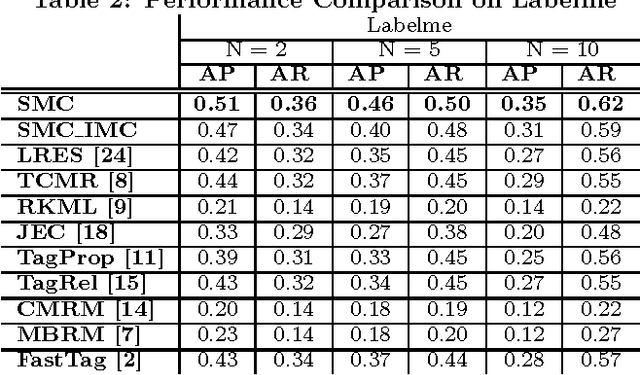
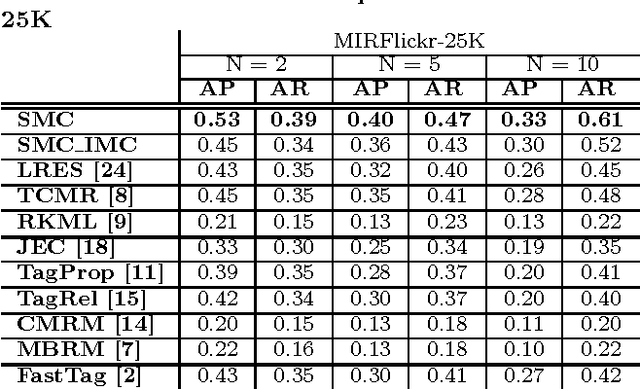
Annotating images with tags is useful for indexing and retrieving images. However, many available annotation data include missing or inaccurate annotations. In this paper, we propose an image annotation framework which sequentially performs tag completion and refinement. We utilize the subspace property of data via sparse subspace clustering for tag completion. Then we propose a novel matrix completion model for tag refinement, integrating visual correlation, semantic correlation and the novelly studied property of complex errors. The proposed method outperforms the state-of-the-art approaches on multiple benchmark datasets even when they contain certain levels of annotation noise.